分层的库设计
每个Subversion核心模块都属于三层中的某一层—版本库层、版本库访问(RA)层或是客户端层(见图 1 “Subversion的架构”)。我们很快就会考察这些层,但首先让我们看一下Subversion库的摘要目录,为了一致性,我们将通过它们的无扩展Unix库名(例如libsvn_fs、libsvn_wc和mod_dav_svn)来引用它们。
libsvn_client
客户端程序的主要接口
libsvn_delta
目录树和文本区别程序
libsvn_diff
上下文区别和合并例程
libsvn_fs
Subversion文件系统库和模块加载器
libsvn_fs_base
Berkeley DB文件系统后端
libsvn_fs_fs
本地文件系统(FSFS)后端
libsvn_ra
版本库访问通用组件和模块装载器
libsvn_ra_dav
WebDAV版本库访问模块
libsvn_ra_local
本地版本库访问模块
libsvn_ra_serf
另一个(实验性的) WebDAV 版本库访问模块
libsvn_ra_svn
一个自定义版本库访问模块
libsvn_repos
版本库接口
libsvn_subr
各色各样的有用的子程序
libsvn_wc
工作拷贝管理库
mod_authz_svn
使用WebDAV访问Subversion版本库的Apache授权模块
mod_dav_svn
影射WebDAV操作为Subversion操作的Apache模块
单词“各色各样的(miscellaneous)”只在列表中出现过一次是一个好的迹象。Subversion开发团队非常注意将功能归入合适的层和库,或许模块化设计最大的好处就是从开发者的角度看减少了复杂性。作为一个开发者,你可以很快就描画出一副“大图像”,以便于你更精确地,也相对容易地找出某一功能所在的位置。
模块化的另一个好处是我们有能力去构造一个全新的,能够完全实现相同API功能的库,以替换整个给定的模块,而又不会影响基础代码。在某种意义上,Subversion已经这样做了。libsvn_ra_dav、libsvn_ra_local、libsvn_ra_serf和libsvn_ra_svn
all都实现了相同的接口,均与版本库层进行通讯—libsvn_ra_loca与版本库直接连接其他几个则通过网络。
libsvn_fs_base和libsvn_fs_fs库是另外一对以不同方式实现相同功能的库—都是可以与libsvn_fs库连接。
客户端本身也得益于Subversion设计的模块化,Subversion的libsvn_client库提供了设计一个Subversion工作客户端(见“客户端层”一节)的绝大多数功能。所以尽管Subversion的发布版只有svn命令行客户端程序,依然有许多第三方的程序提供了各种形式的图形化客户端UI。这些GUI使用的API与命令行客户端完全相同。模块化类型的API的促使了大量Subversion客户端和IDE集成插件使用Subversion本身。
版本库层
当提到Subversion版本库层时,我们通常会讨论两个基本概念—版本化文件系统实现(通过libsvn_fs访问,libsvn_fs_base和libsvn_fs_fs支持),和包装在外的(以libsvn_repos实现)版本库逻辑。这些库提供了版本控制数据的存储和报告机制,这些层通过版本库访问层连接客户端层,从Subversion用户的角度,这些事情在整个过程的另一端。
Subversion文件系统通过libsvn_fs
API来访问,它并不是一个安装在操作系统之上的内核级的文件系统(例如Linux
ext2或NTFS),而是一个虚拟文件系统。它并未将“文件”和“目录”保存为真实的文件和目录(也就是用你熟知的shell程序可以浏览的那种),而是采用了一种抽象的后端存储方式,这个后端存储方式有两种—一个是Berkeley
DB数据库环境,另一个是普通文件表示。(要了解更多关于版本库后端的信息,请看“选择数据存储格式”一节)。除此之外,开发社区也非常有兴趣考虑在Subversion的未来版本
中提供某种使用其它后端数据库系统的能力,也许是开放式数据库连接(ODBC)的机制。实际上,Google在2006中期启动Google
Code主机服务项目之前做了一些类似的事情,它的部分开源项目组成员编写了新的Subversion文件系统,使用了他们的扩展性极好的Bigtable数据存储。
libsvn_fs支持的文件系统API包含了所有其他文件系统的功能:你可以创建和删除文件和目录、拷贝和移动、修改文件内容等等。它也包含了一些不太常用的特性,如对任意文件和目录添加、修改和删除元数据(“properties”)的能力。此外,Subversion文件系统是一个版本化的文件系统,意味着你修改你的目录树时,Subversion会记住修改以前的样子。也可以回到所有初始化版本库之后(且仅仅之后)的版本。
所有你对目录树的修改包含在Subversion事务的上下文中,下面描述了修改文件系统的例程:
开始 Subversion 的提交事务。
作出修改(添加、删除、属性修改等等。)。
提交事务。
一旦你提交了你的事务,你的文件系统修改就会永久的作为历史保存起来,每个这样的周期会产生一个新的树,所有的修订版本都是永远可以访问的一个不变的快照。
事务的其它信息
Subversion的事务概念,特别是在libsvn_fs中的数据库附近的代码,很容易与低层提供支持的数据库事务混淆。两种类型事务都提供了原子和隔离操作,换句话说,事务给你能力可以用“全部或者没有”样式执行一系列的动作—所有的动作都完全成功,或者是所有的没有发生—而且不会干扰别人操作数据。
数据库事务通常围绕着一些对数据库本身的数据修改相关的小操作(如修改表行的内容),Subversion是更大范围的事务,围绕着一些高一级的操作,如下一个修订版本文件系统的一组文件和目录的修改。如果这还不是很混乱,考虑这个:Subversion在创建Subversion事务(所以如果Subversion创建事务失败,数据库会看起来我们从来没有尝试创建)时会使用一个数据库事务!
很幸运的是用户的文件系统API,数据库提供的事务支持本身几乎完全从外表隐藏(也是一个完全模块化的模式所应该的)。只有当你开始研究文件系统本身的实现时,这些事情才可见(或者是开始感兴趣)。
大多数文件系统接口提供的功能作为一个动作发生在一个文件系统路径上,也就是,从文件系统的外部,描述和访问文件和目录独立版本的主要机制是经过如/foo/bar的路径,就像你在喜欢的shell程序中定位文件和目录。你通过传递它们的路径到相应的API功能来添加新的文件和目录,查询这些信息也是同样的机制。
然而,不像大多数文件系统,一个单独的路径不足以在Subversion定位一个文件或目录,可以把目录树看作一个二维的系统,一个节点的兄弟代表了一种从左到右的动作,并且递减到子目录是一个向下的动作,图 8.1 “二维的文件和目录”展示了一个典型的树的形式。
图 8.1. 二维的文件和目录
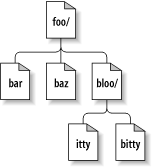
当然,Subversion文件系统有一个其它文件系统所没有的第三维—时间![49]在一个文件系统接口,几乎所有的功能都有个路径(path)参数,也期望一个root参数。svn_fs_root_t参数不仅描述了一个修订版本或一个Subversion事务(通常正好是一个修订版本),而且提供了用来区分修订版本32的/foo/bar和修订版本98在同样路径的三维上下文环境。图 8.2 “版本时间—第三维!”展示了修订版本历史作为添加的纬度进入到Subversion文件系统领域。
图 8.2. 版本时间—第三维!
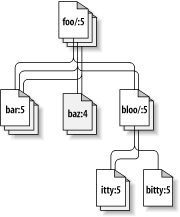
像之前我们提到的,libsvn_fs的API感觉像是其它文件系统,只是有一个美妙的版本化能力。它设计为为所有对版本化的文件系统有兴趣的程序使用,不是巧合,Subversion本身也对这个功能很有兴趣。但是虽然文件系统API一定必须对基本的文件和目录版本化提供足够的支持,Subversion需要的更多—这是libsvn_repos到来的地方。
Subversion版本库库(libsvn_repos)建立在(逻辑上讲)libsvn_fs的API之上,不仅仅提供了版本化文件系统的功能,它没有包裹所有的文件系统功能—只有文件系统常规周期中的主要事件使用版本库接口包裹,如包括Subversion事务的创建和提交,修订版本属性的修改。这些特别的事件使用版本库库包裹是因为它们有一些关联的钩子。版本库钩子系统并没有与与版本化文件系统的紧密关联,所以它们存在于版本库的包裹库。
钩子机制需求是从文件系统代码的其它部分中抽象出单独的版本库库的一个原因,libsvn_repos的API提供了许多其他有用的工具,它们可以做到:
在Subversion版本库和版本库包括的文件系统的上创建、打开、销毁和执行恢复步骤。
描述两个文件系统树的区别。
关于所有(或者部分)修订版本中的文件系统中的一组文件的提交日志信息的查询
产生可读的文件系统“导出”,一个文件系统修订版本的完整展现。
解析导出格式,加载导出的版本到一个不同的Subversion版本库。
伴随着Subversion的发展,版本库库会随着文件系统提供更多的功能和配置选项而不断成长。
版本库访问层
如果说Subversion版本库层是在“这条线的另一端”,那版本库访问层就是这条线。负责在客户端库和版本库之间编码数据,这一层包括libsvn_ra模块加载模块,RA模块本身(现在包括了libsvn_ra_dav、libsvn_ra_local、libsvn_ra_serf和libsvn_ra_svn),和所有一个或多个RA模块需要的附加库,例如与Apache模块mod_dav_svn通讯的libsvn_ra_dav或者是libsvn_ra_svn的服务器,svnserve。
因为Subversion使用URL来识别版本库资源,URL模式的协议部分(通常是file:、http:、https:或svn:)用来监测那个RA模块用来处理通讯。每个模块注册一组它们知道如何“说话”的协议,所以RA加载器可以在运行中监测在手边的任务中使用哪个模块。通过运行svn –version,你可以监测Subversion命令行客户端所支持的RA模块和它们声明支持的协议:
$ svn --version svn, version 1.4.3 (r23084) compiled Jan 18 2007, 07:47:40 Copyright (C) 2000-2006 CollabNet. Subversion is open source software, see http://subversion.tigris.org/ This product includes software developed by CollabNet (http://www.Collab.Net/). The following repository access (RA) modules are available: * ra_dav : Module for accessing a repository via WebDAV (DeltaV) protocol. - handles 'http' scheme - handles 'https' scheme * ra_svn : Module for accessing a repository using the svn network protocol. - handles 'svn' scheme * ra_local : Module for accessing a repository on local disk. - handles 'file' scheme $
RA层导出的API包含了发送和接收版本化数据的必要功能,并且每一个存在的RA插件可以使用特定协议执行任务—libsvn_ra_dav同配置了mod_dav_svn模块的Apache
HTTP服务器使用HTTP/WebDAV(可选SSL加密)通讯,libsvn_ra_svn同svnserve使用自定义网络协议通讯。
对那些一直希望使用另一个协议来访问Subversion版本库的人,正好是为什么版本库访问层是模块化的!开发者可以简单的编写一个新的库来在一侧实现RA接口并且与另一侧的版本库通讯。你的新库可以使用存在的网络协议,或者发明你自己的。你可以使用进程间的通讯调用,或者—让我们发狂,我们会吗?—你甚至可以实现一个电子邮件为基础的协议,Subversion提供了API,你提供创造性。
客户端层
在客户端这一面,Subversion工作拷贝是所有动作发生的地方。大多数客户端库实现的功能是为了管理工作拷贝的目的实现的—满是文件子目录的目录是一个或多个版本库位置的可编辑的本地“影射”—从版本库访问层来回传递修改。
Subversion的工作拷贝库,libsvn_wc直接负责管理工作拷贝的数据,为了完成这一点,库会在工作拷贝的每个目录的特殊子目录中保存关于工作拷贝的管理性信息。这个子目录叫做.svn,出现在所有工作拷贝目录里,保存了各种记录了状态和用来在私有工作区工作的文件和目录。对那些熟悉CVS的用户,.svn子目录与CVS工作拷贝管理目录的作用类似,关于.svn管理区域的更多信息,见本章的“进入工作拷贝的管理区”一节。
Subversion客户端库libsvn_client具备最广泛的职责;它的工作是结合工作拷贝库和版本库访问库的功能,然后为希望普通版本控制的应用提供最高级的API。举个例子,svn_client_checkout()方法是用一个URL作为参数,传递这个URL到RA层然后在特定版本库打开一个会话。然后向版本库要求一个特定的目录树,然后把目录树发送给工作拷贝库,然后把完全的工作拷贝写到磁盘(.svn目录和一切)。
客户端库是为任何程序使用设计的,尽管Subversion的源代码包括了一个标准的命令行客户端,用客户端库编写GUI客户端也是很简单,Subversion新的GUI(或者任何新的客户端,真的)不需要紧密围绕包含的命令行客户端—他们对具有相同功能、数据和回调机制的libsvn_client的API有完全的访问权利。事实上,Subversion源代码中包含了一段C程序(可以在tools/examples/minimal_client.c)例子,演示了如何利用Subversion客户端创建简单的客户端程序。
直接绑定—关于正确性
为什么GUI程序要直接访问libsvn_client而不以命令行客户端的包裹运行?除了效率以外,这也关系到潜在的正确性问题。一个命令行客户端程序(如Subversion提供的)如果绑定了客户端库,需要将反馈和请求数据字节从C翻译为可读的输出,这种翻译是有损耗的,程序不能得到API所提供的所有信息,或者是得到紧凑的信息。
如果你已经包裹了这样一个命令行程序,第二个程序只能访问已经经过解释的(如我们提到的,不完全)信息,需要再次转化为它本身的展示格式。由于各层的包裹,原始数据的完整性越来越难以保证,结果很像对喜欢的录音带或录像带反复的拷贝(一个拷贝…)。
但是关于直接绑定API使用,而不是包裹程序,这是Subversion项目对其API兼容性的承诺。在小版本的变化(如从1.3到1.4)中API的不会有函数原形的改变,简单来说就是你不需要将你程序源代码升级,因为你只是升级到了一个新版本的Subversion。某些方法可能会被废弃,但依然工作,这给你了缓冲时间来最终适应新API。Subversion的命令行输出没有这种兼容性承诺,可能会在每个版本更改。
[49] 我们理解这一定会给科幻小说迷带来一个震撼,他们认为时间是第四维的,我们要为提出这样一个不同理论的断言而伤害了他们的作出道歉。